
Google says new TurboQuant compression can lower AI memory usage without sacrificing quality
- TurboQuant reduces large language model memory usage by up to 6x without degrading output quality.
- The algorithm boosts AI processing speed by up to 8x on modern accelerators, enhancing efficiency.
- PolarQuant and Quantized Johnson-Lindenstrauss techniques enable high-fidelity vector compression.
- TurboQuant’s compatibility with existing models allows easy adoption without retraining.
Memory consumption remains a critical bottleneck for deploying large-scale AI models, especially in resource-constrained environments like mobile devices. Google’s newly introduced TurboQuant compression algorithm addresses this challenge by drastically lowering the memory footprint of large language models (LLMs) while preserving the quality of their outputs. This breakthrough enables faster, more efficient AI applications without sacrificing accuracy, marking a significant step forward in AI model optimization.
By innovatively compressing the key-value cache—a fundamental component that stores intermediate computations—TurboQuant achieves up to a sixfold reduction in memory use and an eightfold increase in processing speed on Nvidia H100 GPUs. This advancement promises to make AI models more accessible, cost-effective, and scalable across diverse hardware platforms, including smartphones and edge devices.
Continue Reading
What is TurboQuant and why does it matter for AI memory usage?
TurboQuant is a novel AI compression algorithm developed by Google Research designed to reduce the memory demands of large language models without compromising their output quality. It specifically targets the key-value cache, which acts as a “digital cheat sheet” storing essential intermediate data to avoid costly recomputation during model inference.
Because LLMs rely on high-dimensional vectors to represent semantic information, these vectors consume substantial memory and can create performance bottlenecks. TurboQuant compresses these vectors more efficiently than traditional methods, enabling models to run faster and with less memory overhead, which is crucial for deploying AI at scale.
How does TurboQuant achieve high compression without quality loss?
TurboQuant’s efficiency stems from a two-step process involving PolarQuant and Quantized Johnson-Lindenstrauss (QJL) techniques:
- PolarQuant: Unlike standard Cartesian encoding (XYZ coordinates), PolarQuant converts vector data into polar coordinates, capturing the radius (magnitude) and angle (direction). This transformation compresses the vector into a more compact form that requires less storage and reduces computational overhead.
- Quantized Johnson-Lindenstrauss (QJL): This step applies a 1-bit error correction layer that reduces residual errors from PolarQuant compression. QJL compresses vectors to a single bit (+1 or -1) while preserving the essential relationships between data points, ensuring that attention mechanisms in neural networks remain accurate.
This combination allows TurboQuant to quantize the key-value cache down to as low as 3 bits per vector without additional retraining, maintaining perfect downstream task performance in benchmark tests.
What are the practical benefits of TurboQuant for AI deployment?
TurboQuant’s advantages extend beyond memory savings:
- Performance acceleration: On Nvidia H100 GPUs, TurboQuant achieves up to 8x faster computation of attention logits compared to uncompressed 32-bit keys, significantly speeding up inference.
- Cost efficiency: By reducing memory requirements, TurboQuant lowers hardware costs for AI workloads, enabling deployment on less expensive or smaller-scale devices.
- Scalability: The algorithm’s compatibility with existing models means organizations can integrate it without expensive retraining or redesign, facilitating rapid adoption.
- Mobile AI enhancement: Compression techniques like TurboQuant can improve the quality and responsiveness of AI on smartphones by reducing reliance on cloud processing and overcoming hardware limitations.
How does TurboQuant compare to traditional quantization methods?
Traditional quantization reduces model precision to shrink size and speed up computation but often at the cost of degraded output quality. TurboQuant, however, maintains output fidelity by leveraging its innovative polar coordinate compression and error correction. This approach avoids the typical trade-offs between compression and accuracy, delivering superior results in both memory savings and model performance.
Technical insights: Understanding the vector compression process
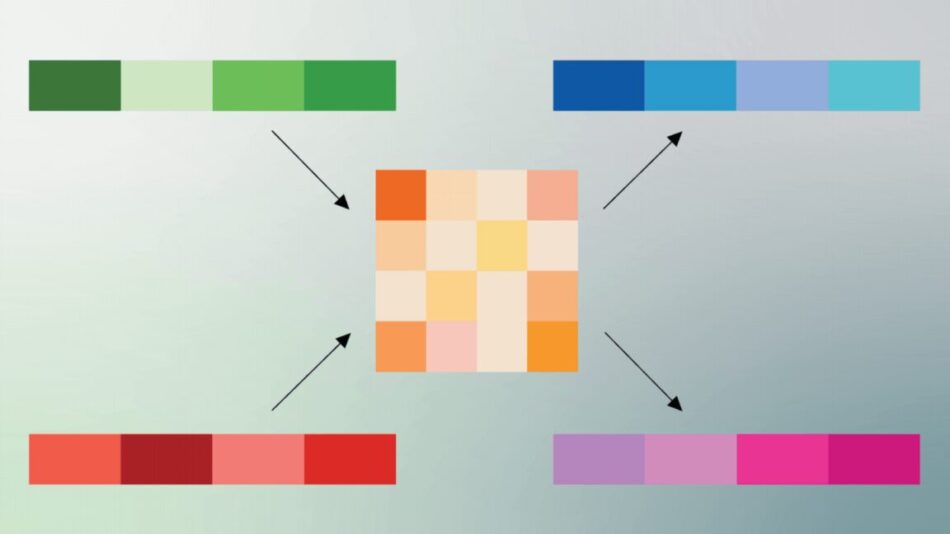
Vectors in AI models represent complex data such as token embeddings or pixel values. Normally encoded in Cartesian coordinates, these vectors require substantial storage. PolarQuant transforms these vectors into polar coordinates, where each vector is represented by a radius and an angle, effectively summarizing magnitude and direction in fewer bits.
Google illustrates this with a real-world analogy: instead of saying “Go 3 blocks East, 4 blocks North” (Cartesian), PolarQuant encodes it as “Go 5 blocks at 37 degrees” (polar), which is more compact and computationally efficient. This reduces the need for expensive normalization and preserves semantic relationships.
Following this, the Quantized Johnson-Lindenstrauss step applies a 1-bit correction that further compresses the data while maintaining accuracy in the neural network’s attention mechanism, which determines the importance of different inputs during processing.
What benchmarks validate TurboQuant’s effectiveness?
Google tested TurboQuant on multiple long-context benchmarks using open-source models like Gemma and Mistral. The results showed that TurboQuant reduced memory usage in the key-value cache by up to 6x while achieving perfect downstream task accuracy. Additionally, it demonstrated an 8x speedup in attention score computation compared to 32-bit unquantized keys on Nvidia H100 accelerators.
These benchmarks confirm that TurboQuant can be applied to existing models without retraining, making it a practical solution for immediate deployment in production environments.
What are the implications of TurboQuant for the future of AI?
TurboQuant represents a significant advancement in AI model compression and optimization. By enabling large models to run efficiently on limited hardware, it opens new possibilities for AI accessibility and scalability. Mobile devices, edge computing, and cloud services can all benefit from reduced memory usage and faster inference times.
Moreover, the freed-up memory could allow developers to run more complex models or increase batch sizes, further enhancing AI capabilities. TurboQuant’s approach may inspire new compression algorithms that balance quality and efficiency, accelerating AI adoption across industries.
Challenges and considerations for implementing TurboQuant
While TurboQuant shows promising results, practical integration requires careful consideration:
- Hardware compatibility: Optimal performance gains are currently demonstrated on Nvidia H100 GPUs; other hardware may require adaptation.
- Model architecture: Although TurboQuant works without retraining, certain model designs might benefit from fine-tuning to maximize compression benefits.
- Error correction trade-offs: The 1-bit Quantized Johnson-Lindenstrauss layer must be balanced to avoid introducing subtle inaccuracies in specific applications.
Ongoing research and development will likely address these challenges to broaden TurboQuant’s applicability.
How can businesses leverage TurboQuant for competitive advantage?
Organizations deploying AI at scale can use TurboQuant to reduce infrastructure costs and improve application responsiveness. Key strategies include:
- Integrating TurboQuant into existing AI pipelines to optimize resource utilization.
- Deploying compressed models on edge devices to enable offline AI capabilities and reduce cloud dependency.
- Scaling AI services more cost-effectively by lowering memory and compute requirements.
- Accelerating innovation cycles by enabling faster experimentation with large models.
These approaches can enhance operational efficiency and unlock new AI-driven business opportunities.
Summary
Google’s TurboQuant compression algorithm offers a breakthrough in reducing the memory footprint of large language models without sacrificing quality. By combining PolarQuant’s polar coordinate compression with Quantized Johnson-Lindenstrauss error correction, TurboQuant achieves up to 6x memory reduction and 8x speed improvements. Its compatibility with existing models and hardware acceleration support make it a practical solution for enhancing AI efficiency across industries, from cloud to mobile.
Frequently Asked Questions
Call To Action
Discover how integrating TurboQuant compression can transform your AI deployments by reducing costs and boosting performance—contact us today to explore tailored solutions for your business.
Note: Provide a strategic conclusion reinforcing long-term business impact and keyword relevance.


